Lous Blog
吴恩达 深度学习 笔记
29 Oct 20191 神经网络和深度学习
第1周 深度学习概率
简要介绍深度学习发展和课程内容
第2周 神经网络基础
logistic回归
m个输入样本x,x为n维列向量
m个输出y,y为二值
数据归一化用sigmoid函数,作为激活函数。提到了Relu激活函数,此函数由于其曲线特性,训练速度会很快。
假设我们认为输入和预测值$\hat{y}$满足如下关系
$ \hat{y}=\sigma(w^T x+b)=P(y=1 \vert x)$
也就是说预测值是代表给定输入x时y=1的概率。因为y只能是0和1,所以根据概率就能计算输出标签。
损失函数
$L( \hat{y},y)=-ylog(\hat{y}) + (1-y)log(1-\hat{y})$
为什么不用$L( \hat{y},y)= \frac{1}{2} (\hat{y}^2 - y^2)$
是为了使求解问题变成凸优化问题。
课程最后解释了,我们希望输出的预测值$\hat{y}$和实际值y
- $y=1 P(y \vert x)=\hat{y}$
- $y=0 P(y \vert x)=1-\hat{y}$
$P(y \vert x)=\hat{y}^y(1-\hat{y})^{(1-y)}$能满足上面两个式子,再由于log是单调的,这个最大就是求负最小。所以损失函数就是这么来的。
整体的概率等于所有样本的概率累积,取了log就变成了求和,除以样本数就是和样本规模无关的损失函数了。
最终的Cost函数就是所有样本损失函数的均值
单次迭代有
$ Z=w^T X + b $
$ A = \sigma(Z) $
$ dZ = A - Y $
$ dw = \frac{1}{m} X dZ^T$
$ db = \frac{1}{m} dZ^T$
$ w = w - \alpha dw $
$ b = b - \alpha db $
这也是为什么就算多个样本也要多次迭代的原因。
个人理解:
和之前理解的训练不一样,最初以为是每个样本单次输入迭代到最后一个样本训练结束。而把所有样本作为单次迭代的训练方法,最后结果应该是接近最优解的。单个样本依次训练可能无法保证。
但是直观上来说,生物体在学习的过程中应该做不到每次都把所有的数据都训练一边。记忆有限,而且在网络训练过程中,早期输入的样本影响会很大,毕竟启蒙教育很重要……
超限学习ELM应该是一次把所有样本代入,直接通过最小二乘法计算权重。对于大量样本的训练可能不适合,这也是为何ELM是一个浅层神经网络。
第3周 浅层神经网络
用一个2层的神经网络作为示例,解释神经网络的正向和反向传播。
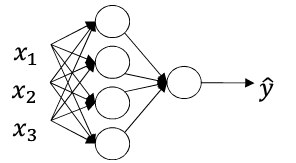
输入层为第0层
有一个隐含层,一个输出层,共2层,每层节点数用$n_l$表示
上图是针对单个样本而言
所有的输入输出样本都是列向量,即矩阵中每一列为一个样本,这点必须得明确。
$z^{[l] (m)}_i$代表第m个样本在第l层第i个神经元的输入
约定[]内代表为层数,()内表示样本数
每个节点其实和之前的logistic是类似的
$\hat{y}=a=g(z)=g(w^T x+b)$
其中$g()$代表激活函数
顺带多介绍了几种激
除了sigmoid,还有tanh、ReLU和泄漏的ReLU
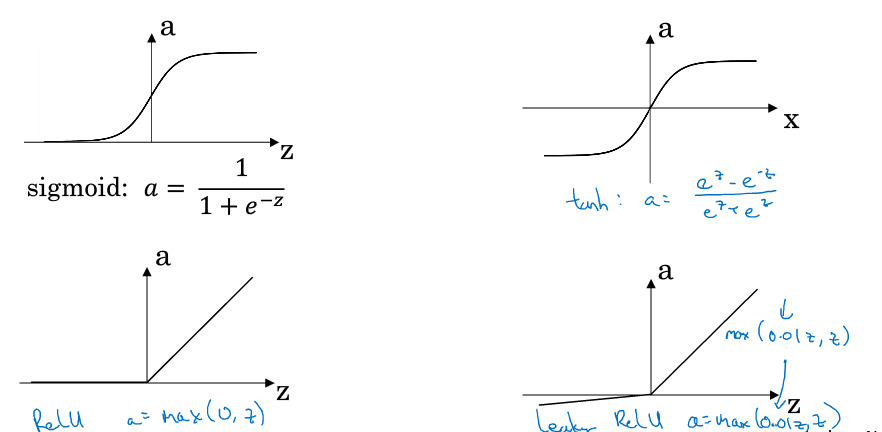
单个样本时
$z^{[l]}_i=w^T_i a^{[l-1]}+b_i$
$z^{[l]}=w^{[l]} a^{[l-1]}+b^{[l]}$
$w$的第i行即代表第i个单元的权重,b为偏置
$w^{[l]}{n_l \times n{l-1}}$
$b^{[l]}_{n_l \times 1}$
m个样本时
$Z^{[l]}=W^{[l]}A^{[l-1]}+B^{[l]}$
$A^{[l]}=g(Z^{[l]})$
为什么会引入非线性的激活函数呢?原因是如果激活函数是线性,那么输入输出之间的关系就是线性的。线性关系何必用深度学习呢……
吴恩达推荐在隐含层使用ReLU,最后一层根据实际情况选择。
反向传播时我们需要计算激活函数的导数$g’(x)$
-
sigmoid $g’(z)=\frac{1}{1+e^{-z}}(1-\frac{1}{1+e^{-z}})=g(z)(1-g(z))$
-
tanh $g’(z)=1-(tanh(z))^2=1-a^2$
-
ReLU $g’(z)=0, z<0$ $g’(z)=1, z \geq 0$
-
Leaky ReLU $g’(z)=0.01, z<0$ $g’(z)=1 , z \geq 0$
神经网络的梯度推导
第i层单元个数为$n^{[i]}$
参数有:
$w^{[1]},b^{[1]},w^{[2]},b^{[2]}$
Cost函数
$J(w^{[1]},b^{[1]},w^{[2]},b^{[2]})=\frac{1}{m} \sum{L(\hat{y},y)}$
$dw^{[l]}=\frac{\partial J}{\partial w^{[l]}}$
$db^{[l]}=\frac{\partial J}{\partial b^{[l]}}$
$w^{[l]}=w^{[l]} - \alpha dw^{[l]}$
$b^{[l]}=b^{[l]} - \alpha db^{[l]}$
正向传播
$Z^{[1]}=W^{[1]}X+b^{[1]}$
$A^{[1]}=g^{[1]}(Z^{[1]})$
$Z^{[2]}=W^{[2]}A^{[1]}+b^{[2]}$
$A^{[2]}=g^{[2]}(Z^{[2]})$
反向传播
$dZ^{[2]}=A^{[2]}-Y$
$dW^{[2]}=\frac{1}{m} dZ^{[2]} {A^{[1]}}^T$
$dB^{[2]}=\frac{1}{m} \sum dZ^{[2]}$
$dZ^{[1]} = {W^{[2]}}^T dZ^{[2]} \times g’^{[1]}(Z^{[1]})$
$dW^{[1]}=\frac{1}{m} dZ^{[1]} X^T$
$dB^{[1]}=\frac{1}{m} \sum dZ^{[1]}$
W在训练开始时应该随机初始化,不能直接全置为0。因为全为0时,整个网络是对称的,每层内单元的权重参数完全一致。偏置可以初始化为0.
并且权重初始化的值应在0左右,因为此时梯度最大,训练效果最好。
第4周 深层神经网络
不知道是不是自己没有理解,感觉主要内容和第二周没啥区别
这个图很直观,对编码有指导意义。
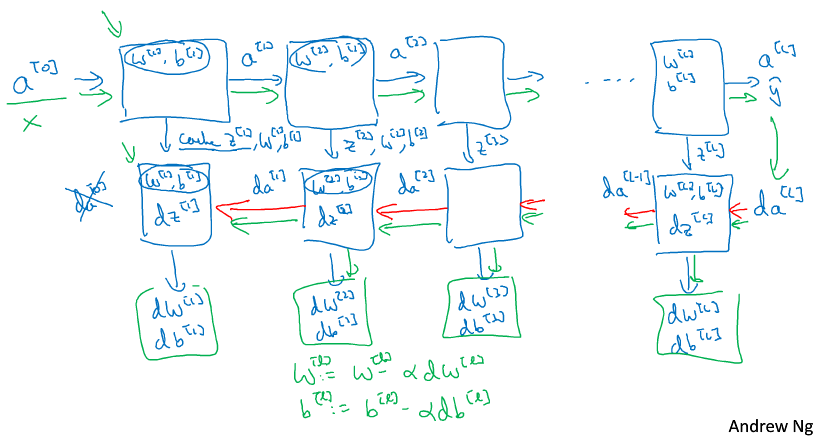
参数:W b
超参数: 激活函数、层数、每层单元个数、迭代次数、学习速度等
个人理解: 这些参数都是人为设定值,并且这个值在网络训练过程中是不变的,我们只是为了得到W和b而设定这些值。
终于理解为啥一些搞深度学习的自嘲在炼丹.这么多参数都要依靠经验,相比之下调PID很有理论支持。
第一个课程基本就是介绍了BP网络,推导和穿插提及了深度网络。
2 改善深层神经网络:超参数调试、正则化以及优化
第1周 深度学习的实用层面
交叉训练,偏差和方差
介绍了过拟合和欠拟合
损失函数引入lambda正则化避免过拟合
通过dropout正则化也能避免过拟合问题,dropout是在训练过程中随机失活神经元。
正则化输入(类似归一化)可以加快训练速度
随着网络加深,会造成梯度消失和梯度爆炸。根据层数L随机初始化权重W可以避免这两个问题。
在训练过程中我们可以对梯度校验来排查代码问题,一般只在调试阶段使用,实际训练过程并不会做校验,主要是校验计算量较大。
第2周 优化算法
mini-batch 每次只随机训练部分样本,和dropout算法类似。
指数加权平均,是为了使优化方向变得更平滑。J下降曲线不出现太多毛刺。
在最优解附近时学习率应该降低,学习率应该随着迭代次数而降低。
momentum、RMSprop、Adam算法
第3周 超参数、Batch正则和框架
超参数在一定范围内随机尝试,自己好好把握……
Batch正则就有意思了,在中间层也尝试把输入输出正则化。貌似说效果还不错,挺符合直觉的。
Softmax多分类器,如何定义softmax的损失函数。
jupter下用tensorflow给了一个简单的示例,tf功能非常强大。
参访了Yoshua Bengio 和林元庆
Yoshua Bengio倾向于理论研究,希望真正的把深度学习的机理摸清楚,再进一步应用。
林元庆应该是更多倾向于落地的,百度深度学习实验室。结合百度应该有不错的产品,PaddlePaddle
3 结构化机器学习项目
确定一些单一化指标
搭建系统原型后再优化
端对端深度学习,没有中间层的预处理或者特征提取,直接用原始输入进行训练。但是可能需要更多的数据。
人脸识别,先定位,提取ROI再做对比。这是目前最好的方案。
翻译,目前可以端对端的训练,因为数据足够多。
4 卷积神经网络
第1周 卷积神经网络
介绍用卷积核计算边缘。
卷积神经网络中权重就变成了卷积核或者过滤器。
卷积网络的输出的单通道代表着某一个特征图像。
经过几层的卷积,就得到了一个尺寸较小但通道较多的特征。向量化这个特征后就可以作为神经网络的输入。后面再接一个softmax或者logistic回归就可以了。
池化
最大池化:固定尺寸区域选项最大值,缩放至指定尺寸。感觉像是一种特殊的resize,只不过缩小的过程中尽可能保存最大的特征差异,类似PCA?
平均池化:不就是最简单的缩放么……
全连接层
卷积层和池化层提取到的特征,作为全连接层的输入。
尽可能参考文献里设置的参数,这些参数可能会适用。(是不是他们也没有搞明白这些参数的作用,但是确实挺好使的)
第2周 深度卷积网络:实例探究
典型网络
- LeNet-5
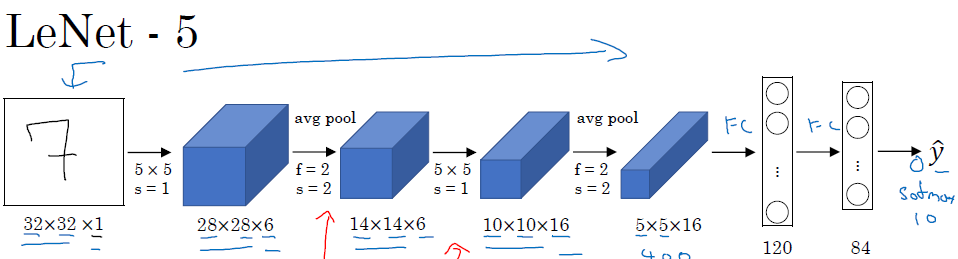
- AlexNet
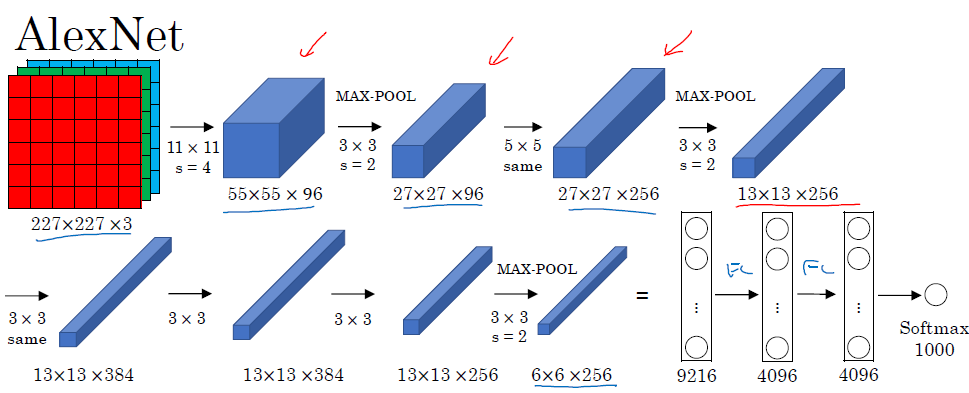
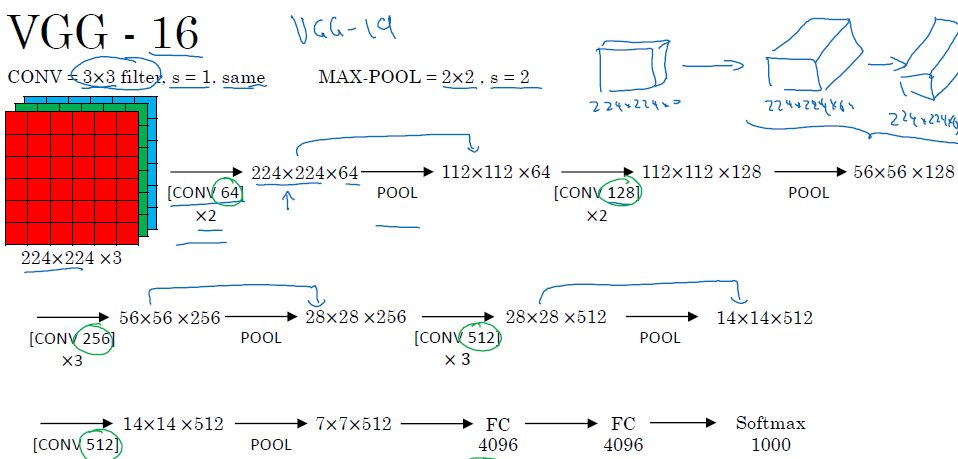
- VGG
ResNet最多152层
把$a^{[l+2]}=g(z^{[l+2]})$替换成$a^{[l+2]}=g(z^{[l+2]}+a^{[l]})$
这样网络的拟合能力就会有较大的适应性,随着层数的变多过拟合的问题也会降低。
1x1的卷积核能降维,等于是把不同维度的特征同时映射到了一个更低维的空间上。
inception
层与层之间定义多种卷积核,通过训练选取出合适的卷积核。有意思。
GooleNet在中间某些层也输入到单独的softmax,确保训练过程不出现过拟合现象,这个操作应该可以推广到所有类型的网络。
迁移网络
- 数据较少的时候,可以下载已经训练好的网络,前面特征提取的网络不变,只训练softmax。
- 数据一般的时候,只训练最后的几层特征提取和softmax。
- 数据较多,可以把训练好的权重作为初始化权重。
随机裁剪、旋转,颜色偏移都可以增加数据量。
第3周 目标检测
训练输入原始图像,输出包含图像标签和图像的位置。